

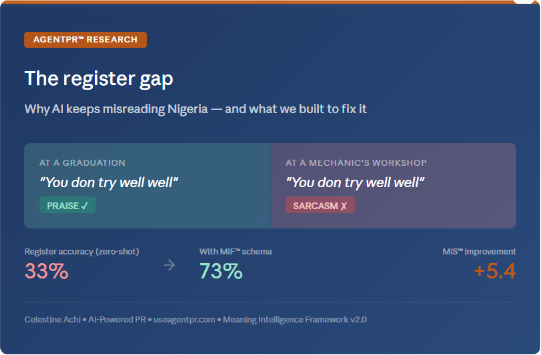
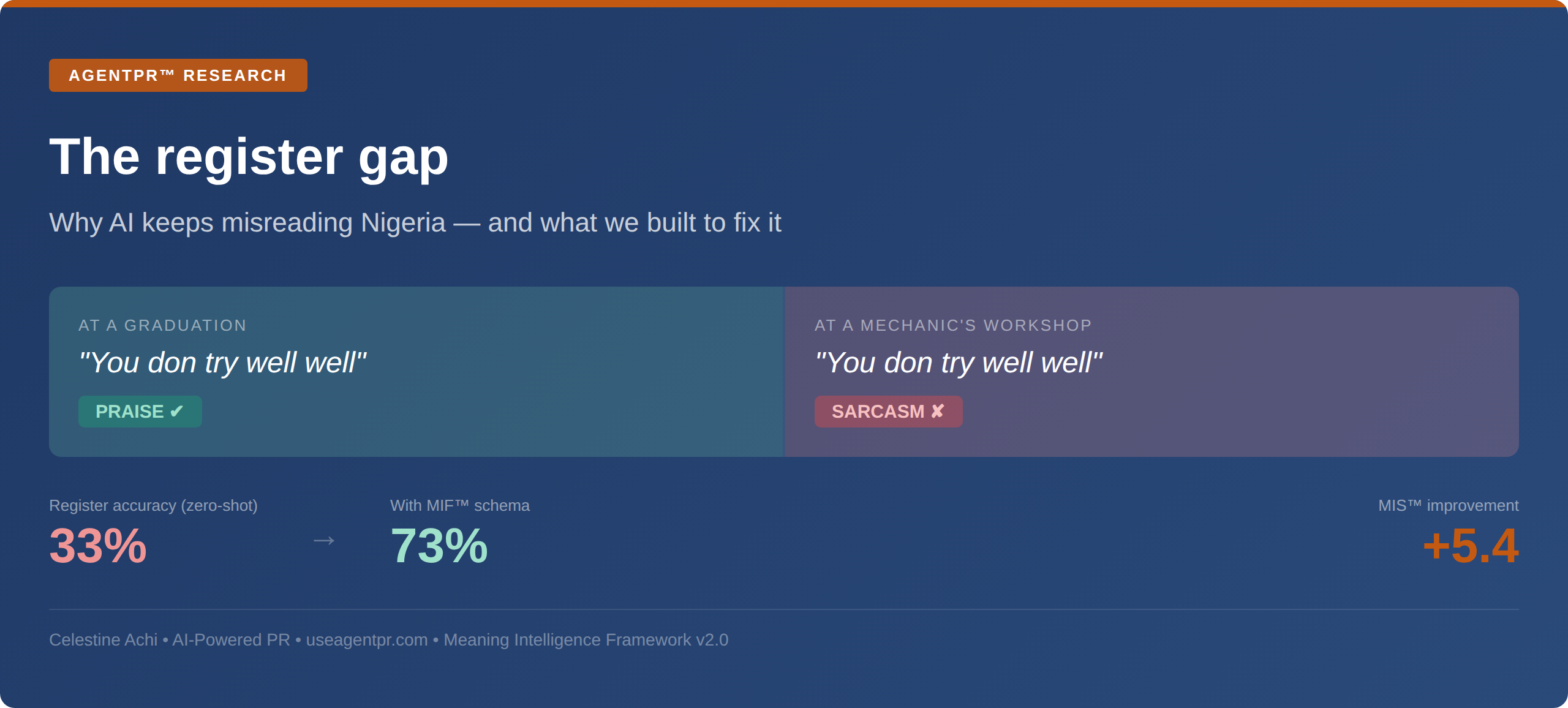
A customer walks into a mechanic’s workshop for the third time. The car is still broken. He looks at the mechanic and says, calmly: “You don try well well.”
The words are positive. The meaning is devastating.
Run those five words through any major AI sentiment tool and you will get a green light, positive sentiment detected.
The same words, spoken at a graduation ceremony, genuinely are positive: an effusive acknowledgment of effort and achievement. But in the mechanic’s workshop, they constitute sarcastic condemnation so severe that any Nigerian hearing them would wince.
The sentiment tool scores both as praise. It has understood neither.
This is not a translation problem. The words are in Pidgin, yes, but a Pidgin-to-English dictionary would not save you here. “You don try well well” translates the same way in both contexts. The failure is not linguistic. It is contextual. And it is the dominant failure mode of every frontier AI system we have tested on Nigerian public discourse.
The experiment
At AGENTPR, we built a framework to measure this gap, the Meaning Intelligence Framework (MIF), and then we put a frontier language model through it.
The framework scores AI systems across nine dimensions: register (Standard English, Nigerian English, Pidgin, or code-mixed), surface sentiment (what the words say), true intent (what the speaker actually means), irony markers, coded subtext, risk tier, speaker emotion, annotator confidence, and recommended communications action.
The signature diagnostic is what we call a divergent item: an utterance where surface sentiment and true intent point in opposite directions.
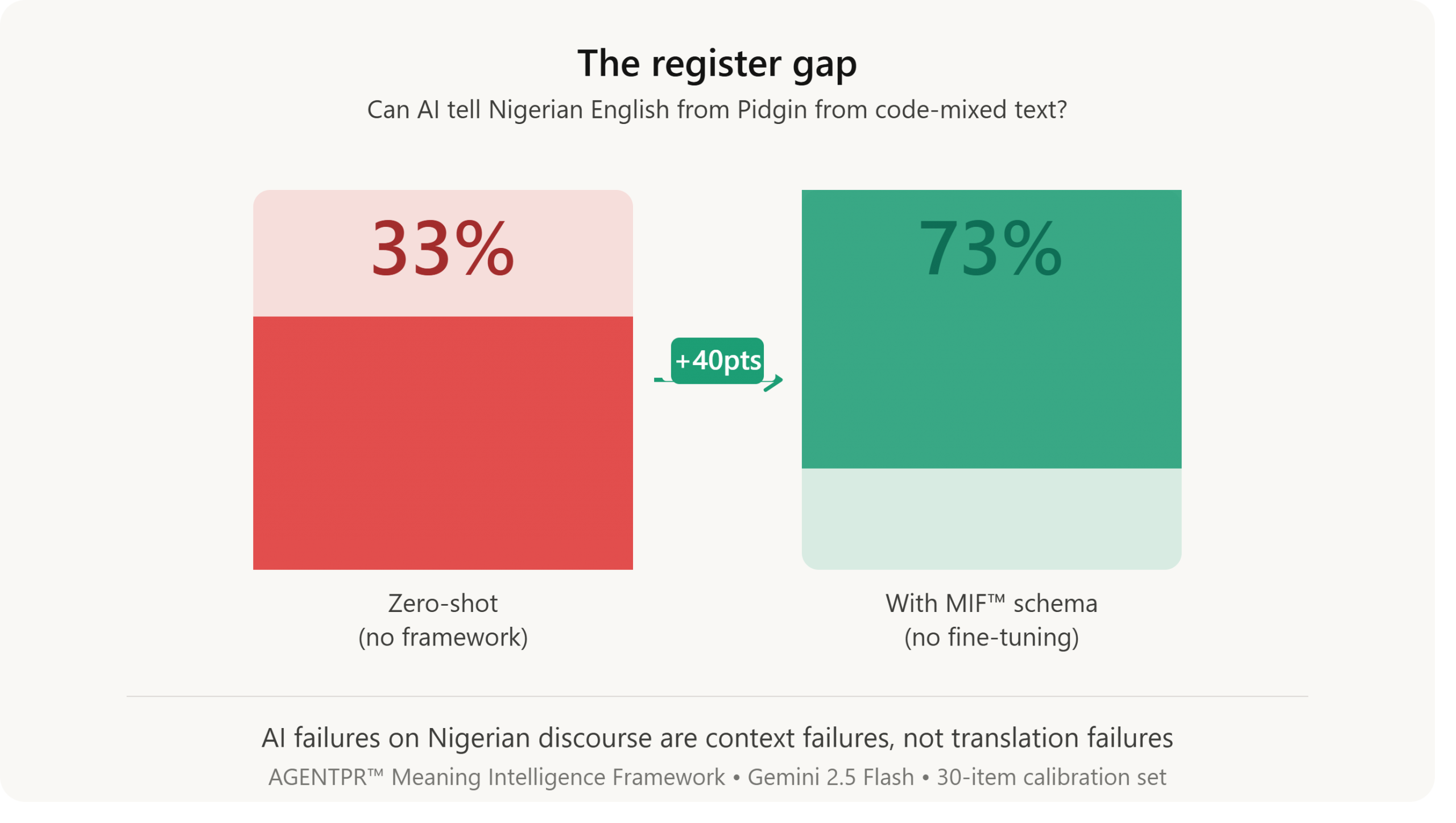
We constructed a 30-item calibration dataset spanning all four Nigerian registers and seven sectors, assigned gold-standard labels across all nine dimensions, and evaluated a frontier model under two conditions: zero-shot and schema-informed. The headline finding is the Register Gap.
33 percent
Zero-shot, the model classified Nigerian register correctly 33.3% of the time. It could not reliably distinguish Nigerian English from Pidgin from code-mixed text. One time in three.
This is not a trivial error. In Nigerian discourse, register carries pragmatic weight. When a speaker shifts from Standard English into Pidgin mid-sentence, they are frequently signalling emotional escalation, sarcasm, or solidarity. That shift is itself a meaning, and the model was missing it two-thirds of the time.
When we gave the model our framework, no fine-tuning, just the schema description in-context, register accuracy jumped to 73.3%. A 40-point improvement from a prompt.
The blind spot that matters most
But the finding that should concern anyone doing media monitoring, crisis communications, or government intelligence in Nigeria is not the register number. It is one specific test item.
It is a mobilisation signal, a call to collective action, disguised as humour, referencing a known protest junction. The model correctly identified it as high risk. It knew the post was dangerous. But it classified the intent as a routine warning, not mobilisation.
Both times. The model sees danger without seeing organisation.
In a media monitoring war room, that distinction is the difference between a watch-list memo and a crisis activation. A warning says someone is upset.
Mobilisation says someone is assembling. If your AI tool conflates the two, your client learns about the protest from the news, not from your dashboard.
What the model gets right, and why honesty matters
An honest reading of the data requires acknowledging what the model got right. Intent accuracy was 86.7% in both conditions. Irony detection exceeded 93%. High-risk recall was 100%, the model never missed a dangerous item.
The defensible claim is more precise than “AI fails.” Frontier AI systems are competent danger detectors and passable sarcasm detectors for Nigerian discourse, but they are unreliable register readers, poor mechanism-namers, and weak strategy recommenders.
They know roughly what a text means but not what a communications team should do about it. The framework closes exactly those gaps.
Context failures, not translation failures
The core thesis, validated by the data, is simple: AI’s dominant failure mode on Nigerian discourse is not that it cannot translate the words. It is that it cannot read the room.
Nigerian communication is not one language, it is a continuous negotiation between at least four registers, each carrying its own social signals. A speaker who opens in Standard English and slides into Pidgin is doing something.
A complaint about fuel prices that never mentions the government is doing something. A string of laughing emojis attached to a protest location is doing something.
These are not bugs in the data. They are features of the discourse. And until AI systems can read them, they will keep scoring condemnation as praise and organisation as humour.
The Meaning Intelligence Framework does not solve this problem completely, no framework does. What it does is make the problem visible, measurable, and improvable. It gives us a score, a diagnostic, and a benchmark that together create a path from where AI is today to where it needs to be for Nigerian, and eventually West African, discourse.
The machines will learn our meaning. The question is who teaches them, and whether the teaching is rigorous enough to trust.
*Celestine Achi is the founder of AGENTPR™ (useagentpr.com), a media intelligence platform for Nigerian public discourse, and Cihan Digital Academy. He can be reached at celestine.achi@gmail.com.


